
目前目标检测领域的深度学习方法主要分为两类:two stage的目标检测算法;one stage的目标检测算法。前者是先由算法生成一系列作为样本的候选框,再通过CNN进行样本分类;后者则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率和定位精度上占优,后者在算法速度上占优。
首先,在介绍Faster R-CNN之前先介绍一下其历史,以便更好记忆Faster R-CNN的改进和优点。
- R-CNN

1、R-CNN算法利用选择性搜索(Selective Search)算法评测相邻图像子块的特征相似度,通过对合并后的相似图像区域打分,选择出感兴趣区域的候选框作为样本输入到CNN内部,
2、选择性搜索算法: 在目标检测时,为了定位到目标的具体位置,通常会把图像分成许多子块(sub-regions / patches),然后把子块作为输入,送到目标识别的模型中。分子块的最直接方法叫滑动窗口法(sliding window approach)。滑动窗口的方法就是按照子块的大小在整幅图像上穷举所有子图像块。这种方法产生的数据量想想都头大。和滑动窗口法相对的是另外一类基于区域(region proposal)的方法。selective search就是其中之一!
在目标检测时,为了定位到目标的具体位置,通常会把图像分成许多子块(sub-regions / patches),然后把子块作为输入,送到目标识别的模型中。分子块的最直接方法叫滑动窗口法(sliding window approach)。滑动窗口的方法就是按照子块的大小在整幅图像上穷举所有子图像块。这种方法产生的数据量想想都头大。和滑动窗口法相对的是另外一类基于区域(region proposal)的方法。selective search就是其中之一!
3、由网络学习候选框和标定框组成正负样本特征,形成对应的特征向量
4、再由支持向量机设计分类器对特征向量分类,最后对候选框以及标定框完成边框回归操作达到目标检测的定位目的。
缺点:训练网络的正负样本候选区域由传统算法生成,使得算法速度受到限制;CNN需要分别对每一个生成的候选区域进行一次特征提取,实际存在大量的重复运算,制约了算法性能。
- SPP-Net

针对卷积神经网络重复运算问题,2015年微软研究院的何恺明等提出一种SPP-Net算法,通过在卷积层和全连接层之间加入空间金字塔池化结构(Spatial Pyramid Pooling)代替R-CNN算法在输入卷积神经网络前对各个候选区域进行剪裁、缩放操作使其图像子块尺寸一致的做法。利用空间金字塔池化结构有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题,更重要的是解决了CNN对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
缺点:和R-CNN算法一样训练数据的图像尺寸大小不一致,导致候选框的ROI感受野大,不能利用BP高效更新权重。
- Fast R-CNN

借鉴SPP-Net算法结构,设计一种ROI pooling的池化层结构,有效解决R-CNN算法必须将图像区域剪裁、缩放到相同尺寸大小的操作。提出多任务损失函数思想,将分类损失和边框回归损失结合统一训练学习,并输出对应分类和边框坐标,不再需要额外的硬盘空间来存储中间层的特征,梯度能够通过RoI Pooling层直接传播。
可以细分为以下四步:

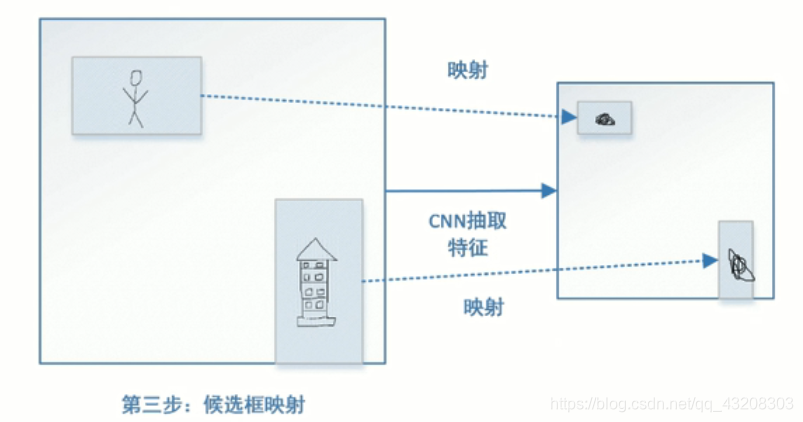
最后就是关键的ROIPooling操作,由于之前提取的候选框很多,大小也都不同,ROI Projection映射到Feature map上也大小不一,为了后面做全连接,需要把这些大小不一的特征Pooling成一样的大小。

缺点:仍然没有摆脱SS生成正负样本候选框的问题,第一步候选框提取时间太长,根据Paper里的统计结果,如果CPU做需要2s per image,而之后的2,3,4三步加起来才用0.3s,Faster R-CNN即针对这一步(压缩提框时间)做的这个改进。
- Faster R-CNN

1、Conv layers:作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
2、 Region Proposal Networks:RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
3、 Roi Pooling:该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
4、 Classification:利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
重点介绍一下RPN(Region Proposal Networks)网络,RPN网络实际分为2条线,上面一条通过softmax分类(分类指的是候选框中是不是有目标物体,而不是对其内部的具体类别进行分类)anchors获得foreground和background(检测目标是foreground),下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。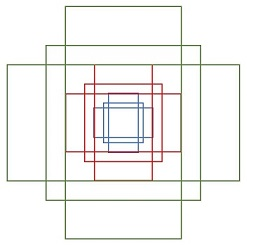
再介绍一下其中的Anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。直接运行论文作者demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
 可以看到一共有 9 个anchors(三个大小,三种形状,with:height∈{1:1, 1:2, 2:1}),而这 9 个 anchors 的作用,就是用来遍历 Conv layers 获得的 feature map(将 anchor 中心点与滑窗中心点进行对其),为每一个点都配备anchors 作为初始的检测框。
可以看到一共有 9 个anchors(三个大小,三种形状,with:height∈{1:1, 1:2, 2:1}),而这 9 个 anchors 的作用,就是用来遍历 Conv layers 获得的 feature map(将 anchor 中心点与滑窗中心点进行对其),为每一个点都配备anchors 作为初始的检测框。
当然,这样获得的检测框不会很准确,但是我们从整个网络来看,后面还会涉及到两次的 b-box regression,这两次回归处理都会对这个位置进行修正。
此外,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
一句话总结:其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!
缺点:由于RPN网络可在固定尺寸的卷积特征图中生成多尺寸的候选框,导致出现可变目标尺寸和固定感受野不一致的现象。
参考:https://www.zhihu.com/search?type=content&q=%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B